One-Class SVM & SVDD

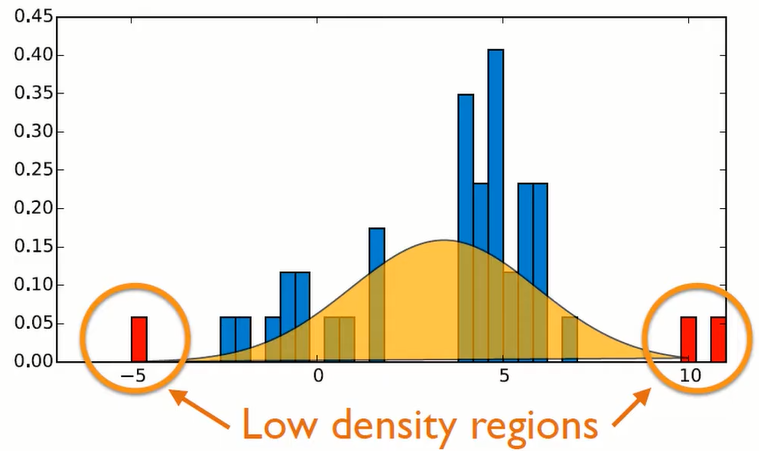
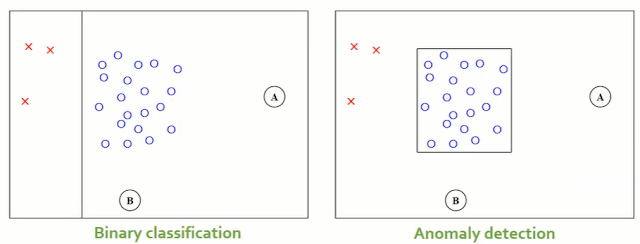
03_6 : Anomaly Detection : Auto-Encoder, 1-SVM, SVDD MoG와 같은 밀도기반 방법론들은 특정 객체가 정상범주에 속할 확률을 구했다. 반면 Support vector 기반 방법론들은 normal과 abnormal을 구분하는 분류경계면을 찾는다. 이번 글에서는 Support vector 기반의 Anomaly detection 방법 중 one-class SVM과 SVDD를 알아보자. One-class Support Vector Machine (1-SVM, OCSVM) 1-SVM의 목표는 Data를 feature space로 mapping 한 뒤, 분류경계면을 통해 mapping된 Data 중 normal data들이 원점으로부터 최대한 멀어지게 만드는 것이다. 위 그림에서 파란색 분류경계면이 (+1) normal data들을 구분하는 것을 확인할 수 있다. 이 목표를 수식화 한 Optimization problem부터 살펴보자. Optimization Problem $$\min_{\textbf{w}}\;\;\;\frac{1}{2}||\textbf{w}||^2 + \frac{1}{\nu l} \sum_{i=1}^l \xi_i - \rho$$ $$s.t.\;\;\;\textbf{w}\cdot \Phi (x_i) \geq \rho - \xi_i\;\;\;\;(i=1,2,\cdots,l),\;\;\xi_i\geq 0$$ $\frac{1}{2}||\textbf{w}||^2$ term은 SVR과 같이 $x$의 변화에 따른 변동이 크지 않도록 Regularization을 하는 term이다. $\rho$는 위 그림에서 주황 직선을 나타내는데, 원점과 분류경계면 Hyperplane과의 거리를 나타낸다. 이 값을 뺌으로써 최소화 문제를 만족하는 최적해일때 $\rho$가 최대가 되도록 한다. (원점에서 Hyperplane이 최대한 멀어지게 만든다) $\frac{1}{\nu l} \sum_{i=1}^l \xi_i$ term은 제약식에 따라 Hyp...